










Gli scienziati hanno sviluppato un modello di intelligenza artificiale che traduce l'attività cerebrale in frasi per aiutare i pazienti che hanno perso l'uso della parola a causa di traumi fisici o ictus
Gli scienziati hanno sviluppato un dispositivo in grado di tradurre in tempo reale i pensieri relativi al linguaggio in parole. Sebbene sia ancora in fase sperimentale, sperano che l'interfaccia cervello-computer possa un giorno aiutare a dare voce a chi non è più in grado di parlare.
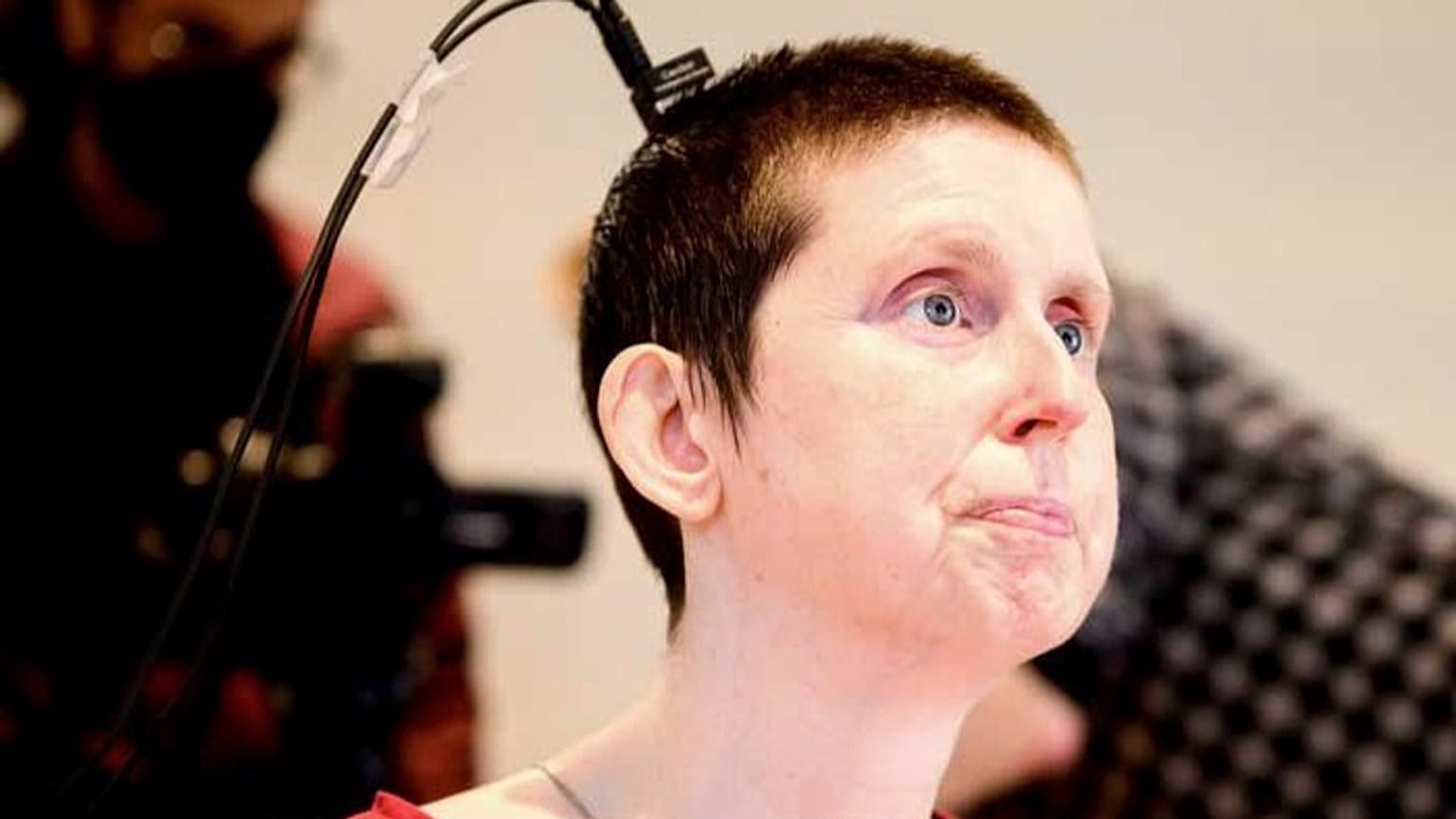
Un nuovo studio descrive la sperimentazione del dispositivo su una donna di 47 anni affetta da tetraplegia, impossibilitata a parlare per 18 anni a causa di un ictus. I medici le hanno impiantato il dispositivo nel cervello durante un intervento chirurgico nell'ambito di una sperimentazione clinica.
Il dispositivo "converte la sua intenzione di parlare in frasi fluenti", ha dichiarato Gopala Anumanchipalli, coautore dello studio, pubblicato sulla rivista Nature Neuroscience.
Le altre interfacce cervello-computer (Bci) per il parlato hanno in genere un leggero ritardo tra il pensiero di frasi e la verbalizzazione computerizzata. Secondo i ricercatori, tali ritardi possono interrompere il flusso naturale della conversazione, causando potenzialmente errori di comunicazione e frustrazione.
Si tratta di "un grande passo avanti nel nostro campo", ha dichiarato Jonathan Brumberg del Laboratorio di Neuroscienze Applicate e Linguaggio dell'Università del Kansas negli Stati Uniti.
Come funziona l'impianto che da voce a chi ha perso la parola
Un'équipe californiana ha registrato l'attività cerebrale della donna con degli elettrodi mentre pronunciava frasi in silenzio nel suo cervello.
Gli scienziati hanno utilizzato un sintetizzatore sviluppato grazie alle registrazioni della voce della donna prima dell'ictus per riprodurre l'emissione. Poi hanno addestrato un modello di intelligenza artificiale (Ai) per tradurre l'attività neurale in suono.
Il funzionamento è simile a quello dei sistemi esistenti usati per trascrivere riunioni o telefonate in tempo reale, ha spiegato Anumanchipalli, dell'Università della California, Berkeley, negli Stati Uniti.
L'impianto viene posizionato sul centro del linguaggio del cervello, così da monitorarne l'attività, e i segnali vengono tradotti in frasi.
Si tratta di un "approccio in streaming", ha detto Anumanchipalli, con ogni frammento di 80 millisecondi, circa mezza sillaba, inviato a un registratore.
"Non si aspetta che la frase finisca", ha detto Anumanchipalli. "La elabora mentre è in fase di formulazione".
Decodificare il parlato così rapidamente consente di tenere il passo con il ritmo del parlato naturale, ha detto Brumberg. L'uso di campioni vocali, ha aggiunto, "sarebbe un progresso significativo nella naturalezza del parlato".
Sebbene il lavoro sia stato parzialmente finanziato dai National institutes of health (Nih) statunitensi, Anumanchipalli ha dichiarato che non è stato influenzato dai recenti tagli alla ricerca dei centri.
Sono necessarie ulteriori ricerche prima che la tecnologia sia pronta per essere utilizzata su larga scala, ma con "investimenti sostenuti" potrebbe essere disponibile per i pazienti entro un decennio.